

Starting out with Mobile Automation Testing
We wanted to share the experience of how we are improving our mobile app automation strategy over time. It’s been a learning experience for us, despite the fact that we have several tasks to deliver. Meanwhile, we still need to keep maintaining our mobile automation tests.
When we first embarked on our mobile automation journey in March 2020, Flip had 50 employees and was struggling with the flow of testing. At that time, we did not have much experience in developing mobile automation and we ran most of the test cases manually. As the time went on, Flip grew faster with many product initiatives and features, and the number of Test Engineers (TE) and Mobile Engineers also increased, but we still focused on doing manual testing to keep up with the product release scope, and we didn’t allocate enough time to write automated tests.
As a result, our regression time got longer in every release. We even reached 3 weeks in one cycle, so we wanted to reduce the manual effort for testing by ensuring all test cases that can be automated will be automated. Our challenge had just started as we didn’t have enough experience and time in developing the mobile automation, and most of our time was spent to complete the feature testing and regression. In order to achieve the scale needed to grow through this phase, we must start utilizing mobile automation tests and having collaboration with Mobile Engineers.
Soon after, we started experimenting with some tools. We found a way to set up mobile automation testing with a comprehensive tool and framework built using WebdriverIO. In the first phase, we started exploring ways to run the mobile automation tests. We found 2 options (Appium and Detox) and decided to go with Appium because of the following reasons:
- Appium supports JavaScript. It was important for our team to have tests written in JavaScript because it is our main programming language for Mobile and Test Engineers.
- Open source, as well as frequently maintained.
- Many communities.
Next, once automation had been added, our next target was to run the mobile automation tests on a schedule using cloud devices. At this stage, we needed to research cloud devices for mobile apps and determined the criteria that meet our requirements. We did a comparison and comprehensive analysis during PoC with selected vendors, and here are some of our criteria:
- Reliable and scalable
- Easier and faster way to set up with our mobile automation framework
- Cost-effective pricing
- Strong customer support team focused on solving issues
Based on those, we made a decision to choose LambdaTest, and set up our test environment to reduce our manual testing process.
In the end, by starting mobile automation testing and also running those tests on a schedule using cloud devices, there are several benefits we gain, including:
- Allowing Mobile Engineers to create the automation tests based on JavaScript independently without the involvement of the Test Engineers.
- Simplifying the test interaction with the application by using WebdriverIO and providing a set of plugins to help create scalable and robust end-to-end test scenarios on mobile devices.
- Creating readable test cases using Jasmine so that non-engineers can also understand our test cases.
- Reducing the regression time by covering more test cases in our end-to-end test.
- Having integrated with cloud devices, we can have a more scalable way to run the automation tests reliably and get the test execution results faster.
Challenges and Obstacles
As we progressed in our journey, we faced several challenges and obstacles along the way:
- Flip users who use Google TalkBack get misleading information from our application.
- We could not identify some elements on iOS, such as the
getText()value. As a result, we couldn’t use it for assertion in our automation tests. - Sometimes we needed to redefine a similar component multiple times, since we had different teams involved working on the same element, and it caused high maintenance, such as:
- Page elements inconsistency
- Unstructured scenarios (in the Jasmine test specification)
- Too many imported files
- A similar function that can actually be reused
After trying to identify the challenges and obstacles, we tried to make some improvements. First, we wanted to fix the first and second issues. We used `accessibilityLabel` as the selector for identifying elements in automation tests, and this caused several problems:
- The `accessibilityLabel` is used in Google TalkBack, the accessibility service for the Android operating system that helps blind and visually impaired users to interact with their devices. In our case, they would have challenges in identifying the UI elements to press. For example, the application will read "LOGIN_SCENE-BUTTON-LOGIN", while it should be called "Login Button".

2. The `getText()` function doesn’t work in iOS and it always returns the value of the `accessibilityLabel` instead of the text value of the element.
We had several options to solve this at that time. First, by changing the `accessibilityLabel` to text information for more readability, for example, our previous `accessibilityLabel` had the attribute name: BUTTON_UPLOAD_RECEIPT_COMPONENT-BUTTON-UPLOAD_RECEIPT, and we changed it to “Upload Receipt Button”. So, users who use Google TalkBack will listen to the correct description of the element. However, problem number two was still not resolved, because the `accessibilityLabel` still replaces both the name and label attributes.
Another solution is to use the `testID` attribute on each element to ensure that the element is always findable via Appium and also readable by Google TalkBack. In the past, we only used `accessibilityLabel`, also known as `accessibility-id` without combining `resource-id` with content-description. We have tried to switch to using `testID` before and found this change was straightforward.
On iOS, both the `testID` and `accessibilityLabel` attributes work in the same way. They first try to match the name attribute and then fall back to the label attribute. If we want to use both the `testID` and `accessibilityLabel` attributes, we know that they correspond to the label and name element attributes respectively. This can be easily verified using Appium Desktop.
On Android, the `testID` and `accessibilityLabel` attributes work differently than on iOS. Instead of using the `accessibility-id` strategy to try to find elements that match the content-desc attribute, the `id` strategy should be used to try to match the `resource-id` element attribute.
And this is how we declare it. For example, from previous content description ONBOARDING_SCENE-VIEW-START_USING_FLIP, we combine the resource id with content description to become “id.flip.staging:id/ONBOARDING_SCENE-VIEW-START_USING_FLIP”.
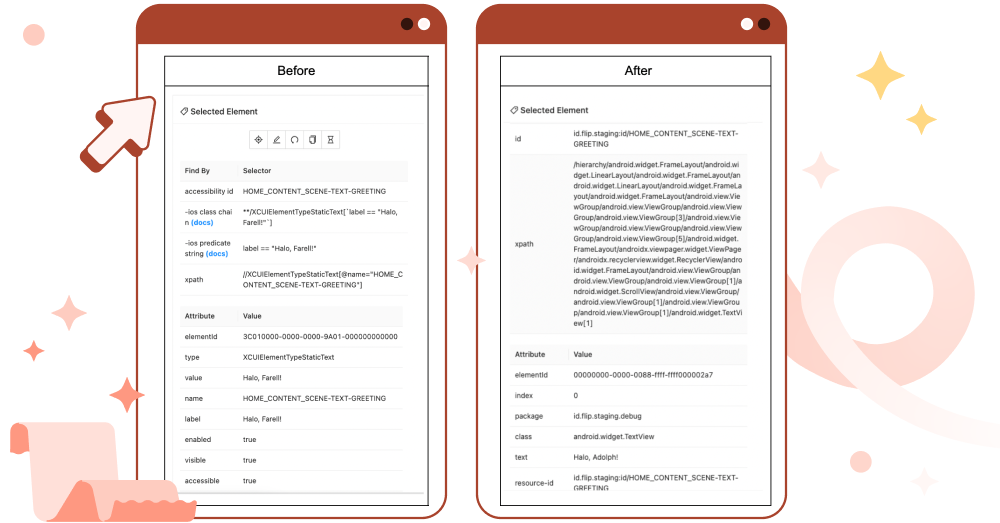
As a result, with this implementation, Flip users who use Google TalkBack will get the correct text information from the screen reader and interact well with the Flip application on their devices. We also have a unique identifier for getting the element via a selector. We can also solve the issue of `getText()` value on iOS and perform more assertions in the automation tests.
After we solved the first and second challenges, we then tried to solve the last one. The last challenge came up since Flip was growing fast with a significant addition of Test Engineers and we needed to maintain our mobile automation tests for each squad. During the development of the mobile automation tests, sometimes we used different practices, and each squad had an independent package folder of their page elements which resulted in page elements or flows (e.g. login flow) to be developed in silos and might end up as duplicates.
To solve it, we implemented the Page Object Model (POM), a design pattern in an automation framework that creates an object repository for storing mobile elements. Using the Page Object Model, each page of an application is represented as a class. Each class contains only the corresponding page elements. Test Engineers then perform test operations using these elements in the application under test.
For some end-to-end test cases that involve repetitive steps, such as Login flow or Registration flow, we also adopt the Facade pattern as an extension of the Page Object Model pattern.
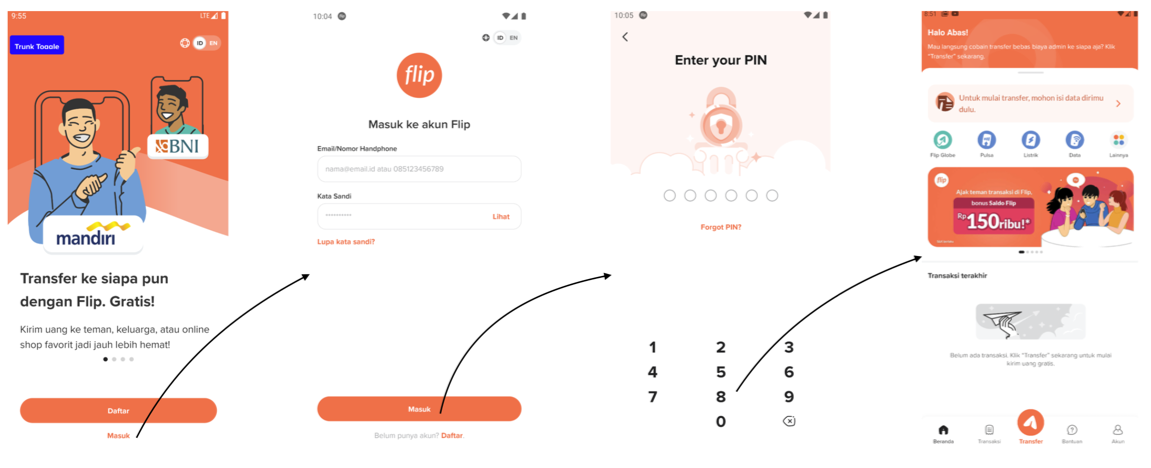
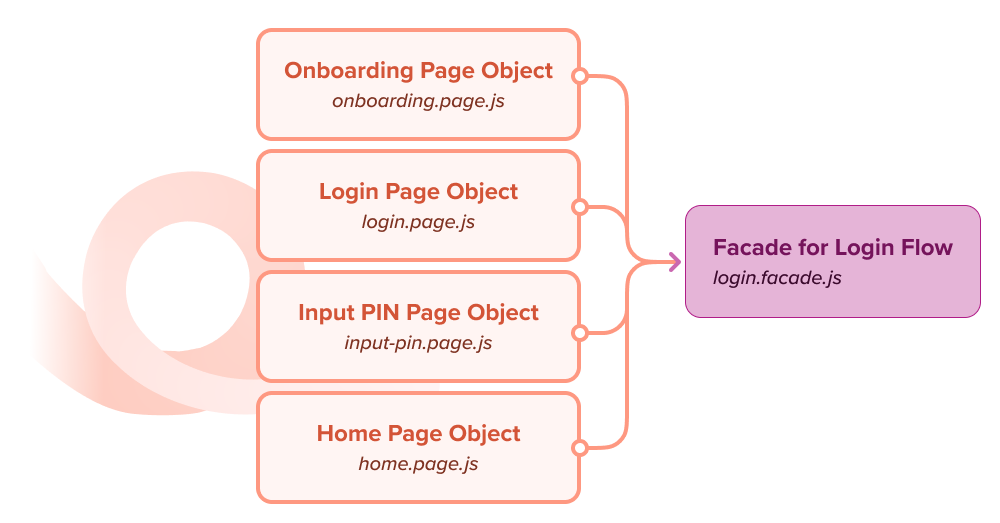
As an example, we commonly use Login flow as a precondition when executing test cases across all teams. By implementing the Facade pattern, we don’t need to deal with each Page Object class individually in our test case. Instead, we can interact directly with the Facade class. In the end, the POM pattern helped us to enhance our test maintenance, reduce code duplication, allow us to easily update page element locators without affecting our test cases, and solve the third challenge that we faced in our mobile test automation journey.
Summary

Before the start of our journey, our regression testing cycle required three weeks to finish and our mobile automation test case coverage was still low below 10%. After some improvements that we have made as part of our journey, now we can shorten our regression testing cycle into seven days and increase the automated test case coverage to 40%, while manual testing covers the rest. With `TestID`, Google TalkBack runs correctly to help the blind and visually impaired users interact with Flip on their devices. Finally, implementing mobile automation with the POM design pattern reduces our code duplication and improves the test case maintenance.
For those who just started your mobile automation journey, full automation may seem a far-off goal. Certainly, it would not be possible to achieve it overnight. Test automation is not a rocket science and its success depends on our strategy to solve problems gradually and tackle the challenges and bottlenecks effectively. All decisions will have pros and cons, but we should choose wisely the solution that is right for the problem we face.
Testing using automated testing is easier, faster, and saves time compared to manual testing. The test code is reusable, and we can easily execute the test cases over and over again. So, what are you waiting for? Let’s start replacing your repeating manual test cases (e.g. in regression phase) with automation tests!
Note: If you want to be a part of us to improve our mobile automation testing, you can find the opportunities here 🐞🏆







{kind=link}